1. 图算融合简介
- 图算融合简单地说就是将几个算子合并成一个复合粒度算子,以提升性能。
- 基本算子的组合理论上可以表达任何现有计算图,但是复合算子有更好的通用组合表达能力,为了兼顾这两样,mindspore提供了图算融合能力,打破算子边界。
- 图算融合可以通过自动分析和优化现有网络计算图逻辑,并结合目标硬件能力,对计算图进行计算化简和替代、算子拆分和融合、算子特例化编译等优化,以提升设备计算资源利用率,实现对网络性能的整体优化。
- 图算融合是通过ms.set_context(enable_graph_kernel=True)开启的,也可以通过(graph_kernel_flags:图算融合的优化选项)来控制,当与enable_graph_kernel冲突时,它的优先级更高,但是graph_kernel_flags更适用于有经验的用户。
2. 图算融合的开启方式
- ms.set_context(enable_graph_kernel=True)
- ms.set_context(graph_kernel_flags=“--opt_level=2 --dump_as_text”)
opt_level:设置优化级别。默认值:2。当opt_level的值大于0时,启动图算融合。可选值包括:
0:关闭图算融合。
1:启动算子的基本融合。
2:包括级别1的所有优化,并打开更多的优化,如CSE优化算法、算术简化等。
3:包括级别2的所有优化,并打开更多的优化,如SitchingFusion、ParallelFusion等。在某些场景下,该级别的优化激进且不稳定。使用此级别时要小心。
3. 图算融合支持的后端和模式
Ascen> d/GPU
GRAPH_MODE/PYNATIVE_MODE
4. 运行脚本及结果分析
使能图算融合
import numpy as np
import mindspore as ms
from mindspore.nn import Cell
import mindspore.ops as ops
ms.set_context(mode=ms.GRAPH_MODE, device_target="GPU")
# save graph ir to view fusion detail.
ms.set_context(save_graphs=2)
# enable graph kernel optimization.
ms.set_context(enable_graph_kernel=True)
class MyNet(Cell):
def construct(self, x):
a = ops.mul(x, 2.0)
res = ops.add(a, 1.0)
return res
x = np.ones((4, 4)).astype(np.float32) * 0.5
net = MyNet()
result = net(ms.Tensor(x))
print("result: {}".format(result))
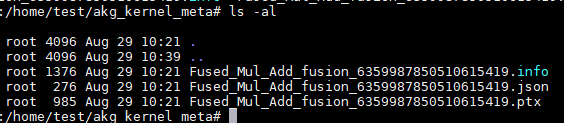
执行完成后,Mul+Add融合成一个算子,所以akg_kernel_meta里面生成了这个算子的json及其他文件
ir图里面也可以看出算子融合了
verbose_ir_files/graph_kernel/0039_stage6_build_4_merge_output_for_update_state_0182.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0036_stage6_build_1_reduce_fake_output_memory_0179.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0042_stage7_postprocess_2_rewrite_output_shape_0185.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0041_stage7_postprocess_1_getitem_tuple_0184.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0028_stage4_highlevelopt2_7_unsorted_segment_sum_atomic_add_process_0171.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0033_stage4_highlevelopt2_12_eliminate_redundant_output_0176.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0026_stage4_highlevelopt2_1_atomic_clean_0169.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0034_stage5_combine_2_compact_tensor_liveness_0177.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0032_stage4_highlevelopt2_11_merge_output_for_update_state_0175.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0037_stage6_build_2_graph_kernel_build_0180.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0022_stage3_split_4_getitem_tuple_0165.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0040_stage7_postprocess_0_shrink_update_state_0183.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0023_stage3_split_5_merge_output_for_update_state_0166.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0029_stage4_highlevelopt2_8_csr_atomic_add_process_0172.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0038_stage6_build_3_getitem_tuple_0181.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0043_stage7_postprocess_3_bind_value_to_graph_0186.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0021_stage3_split_3_graph_kernel_splitter_0164.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0035_stage6_build_0_extend_output_for_update_state_0178.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0030_stage4_highlevelopt2_9_optimize_assign_0173.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0024_stage3_split_6_graph_kernel_cse_0167.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0025_stage3_split_7_eliminate_redundant_output_0168.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0027_stage4_highlevelopt2_6_tensor_scatter_add_atomic_add_to_first_tensor_0170.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
verbose_ir_files/graph_kernel/0031_stage4_highlevelopt2_10_extend_output_for_update_state_0174.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
trace_code_graph_0189:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
hwopt_comm_after_eliminate_nopnode_kernel_graph_0_0187.ir:14:node_name : Fused_Mul_Add_fusion_11050467292232415297
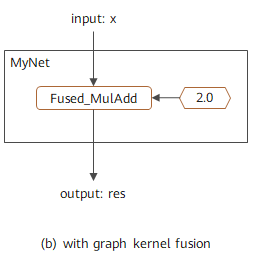
它的执行方式如下图所示
关闭算子融合
import numpy as np
import mindspore as ms
from mindspore.nn import Cell
import mindspore.ops as ops
ms.set_context(mode=ms.GRAPH_MODE, device_target="GPU")
# save graph ir to view fusion detail.
ms.set_context(save_graphs=2)
# enable graph kernel optimization.
ms.set_context(enable_graph_kernel=False)
class MyNet(Cell):
def construct(self, x):
a = ops.mul(x, 2.0)
res = ops.add(a, 1.0)
return res
x = np.ones((4, 4)).astype(np.float32) * 0.5
net = MyNet()
result = net(ms.Tensor(x))
print("result: {}".format(result))
执行完成后,Mul+Add未融合成一个算子,所以akg_kernel_meta不存在

ir图中也没有Mul_Add的算子
![]()
grep “Add” trace_code_graph_0146

从上面的图上可以看出Add是独立算子而不是融合算子
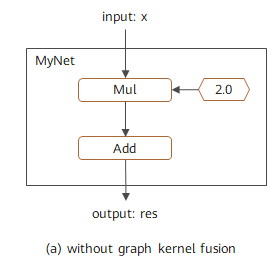
它的执行方式如下图所示:
开启图算融合,不仅可以让基本算子进行融合,也可以让自定义算子进行融合,自定义算子与基本算子进行融合