
在Pynative模式下出现了这个错误,我改了batchsize,还有其它参数,都没有办法解决。
算子的这些文件都能正常生成,所以我判断模型应该是没有问题,是参数设置上的问题,但是一直没有办法解决。
用户您好,欢迎使用mindspore,已经收到您的问题,会尽快分析答复~
跑的具体啥模型代码?这个可能和代码有关,也可能和环境有关,需要有代码和具体环境排查;比如昇思大模型平台上910b环境跑mindyolo就会出现这个错误,但mindYolo在其它环境测试均可以运行,华为云modelarts的910b,或者启智社区的910b,或者我自己的310P环境都可以,这种就肯定是昇思大模型平台环境的问题;
可以换个环境试试,或者跑下其它代码看看,通过对比确认下是不是环境本身的问题;
GaussianLSS的模型。环境是ms-2.6, py39的镜像.
我用的是modelart上的镜像,环境配置应当是没有问题的。
因为我没有其它地方的算力资源,以及试错成本较大,所以我想知道是否有其它其它办法可以排除错误。
下面是我的train文件。
import multiprocessing as mp
import atexit
import os
设置环境变量
os.environ[‘OMP_NUM_THREADS’] = ‘1’
os.environ[‘MS_DEV_SAVE_GRAPHS’] = ‘1’
设置多进程启动方法
try:
if not mp.get_start_method(allow_none=True):
mp.set_start_method(‘fork’, force=True)
except RuntimeError:
pass # 上下文已设置
注册退出清理函数
def cleanup_multiprocessing():
try:
children = mp.active_children()
for child in children:
if child.is_alive():
child.terminate()
child.join(timeout=1)
except:
pass
atexit.register(cleanup_multiprocessing)
import sys
import argparse
import yaml
import time
import logging
from pathlib import Path
from typing import Dict, Any
Add src to path
sys.path.insert(0, str(Path(file).parent.parent / ‘src’))
import mindspore as ms
import mindspore.nn as nn
import mindspore.dataset as ds
from mindspore import context, Tensor
from mindspore.train import Model
from mindspore.train.callback import (
LossMonitor, TimeMonitor, CheckpointConfig,
ModelCheckpoint, LearningRateScheduler
)
from mindspore.communication.management import init, get_rank, get_group_size
优化MindSpore数据集配置以避免信号量泄漏
ds.config.set_num_parallel_workers(1) # 减少并行工作进程
ds.config.set_prefetch_size(4) # 减少预取大小
ds.config.set_seed(42) # 设置随机种子
from models import GaussianLSS
from data import create_dataloader
from losses import GaussianLoss
from utils.visualization import plot_training_curves
class GaussianLSSTrainer:
“”“Complete trainer for GaussianLSS model.”“”
def __init__(self, config_path: str):
"""Initialize trainer with configuration."""
# Load configuration
with open(config_path, 'r') as f:
self.config = yaml.safe_load(f)
# Setup logging
self.setup_logging()
# Setup device
self.setup_device()
# Initialize components
self.model = None
self.train_dataloader = None
self.val_dataloader = None
self.loss_fn = None
self.optimizer = None
self.lr_scheduler = None
self.logger.info("🚀 GaussianLSS Trainer initialized")
self.logger.info(f" Config: {config_path}")
self.logger.info(f" Device: {self.config['ascend']['device_target']}")
def setup_logging(self):
"""Setup logging configuration."""
log_config = self.config.get('logging', {})
log_level = getattr(logging, log_config.get('log_level', 'INFO'))
# Create log directory
log_dir = Path(log_config.get('log_dir', './logs'))
log_dir.mkdir(parents=True, exist_ok=True)
# Setup logger
logging.basicConfig(
level=log_level,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(log_dir / 'train.log'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def setup_device(self):
"""Setup MindSpore device configuration."""
ascend_config = self.config.get('ascend', {})
# Set device target
device_target = ascend_config.get('device_target', 'Ascend')
device_id = ascend_config.get('device_id', 0)
context.set_context(
mode=context.PYNATIVE_MODE, # 临时改为动态图模式进行调试
save_graphs=False
)
ms.set_device("Ascend", 0)
# 设置使用MS后端而不是GE后端,避免子图下沉问题
if device_target == 'Ascend':
# 根据配置设置后端选项
if ascend_config.get('force_ms_backend', True):
context.set_context(
runtime_num_threads=1, # 设置运行时线程数
inter_op_parallel_num=1, # 设置算子间并行数
enable_compile_cache=False, # 禁用编译缓存避免GE后端问题
compile_cache_path="", # 清空编译缓存路径
)
if ascend_config.get('disable_ge_backend', True):
# 强制使用MS后端
os.environ['MS_DEV_FORCE_ACL'] = '0' # 禁用ACL强制使用
os.environ['MS_ENABLE_GE'] = '0' # 禁用GE后端
os.environ['MS_ENABLE_REF_MODE'] = '0' # 禁用引用模式
os.environ['MS_ENABLE_SUBGRAPH_SINK'] = '0' # 禁用子图下沉
self.logger.info("🔧 Configured to use MS backend instead of GE backend")
# Enable optimizations
if ascend_config.get('enable_graph_kernel', True):
context.set_context(enable_graph_kernel=True)
if ascend_config.get('enable_reduce_precision', True):
context.set_context(enable_reduce_precision=True)
# Memory configuration
max_device_memory = ascend_config.get('max_device_memory', '30GB')
context.set_context(max_device_memory=max_device_memory)
self.logger.info(f"✅ Device setup completed: {device_target}:{device_id}")
def build_model(self):
"""Build GaussianLSS model."""
self.logger.info("🏗️ Building GaussianLSS model...")
# Create model
self.model = GaussianLSS(self.config.get("model", {}))
# Load pretrained weights if specified
pretrained_path = self.config.get('paths', {}).get('pretrained_weights')
if pretrained_path and Path(pretrained_path).exists():
self.logger.info(f"Loading pretrained weights from {pretrained_path}")
param_dict = ms.load_checkpoint(pretrained_path)
ms.load_param_into_net(self.model, param_dict)
# Model info
model_info = self.model.get_model_info()
self.logger.info("Model Information:")
for key, value in model_info.items():
self.logger.info(f" {key}: {value}")
self.logger.info("Model built successfully")
def build_dataloaders(self):
"""Build training and validation dataloaders."""
self.logger.info("Building dataloaders...")
data_config = self.config['dataset']
dataloader_config = self.config['dataloader']
# Training dataloader
self.logger.info("Creating training dataloader...")
self.train_dataloader = create_dataloader(
data_root=data_config['data_root'],
config=data_config,
split='train',
**dataloader_config['train']
)
# Validation dataloader
self.logger.info("Creating validation dataloader...")
self.val_dataloader = create_dataloader(
data_root=data_config['data_root'],
config=data_config,
split='val',
**dataloader_config['val']
)
# Show dataloader info
train_info = self.train_dataloader.get_performance_info()
val_info = self.val_dataloader.get_performance_info()
self.logger.info("Dataloader Information:")
self.logger.info(f" Training samples: {train_info.get('num_samples', 'Unknown')}")
self.logger.info(f" Validation samples: {val_info.get('num_samples', 'Unknown')}")
self.logger.info(f" Training batch size: {train_info['batch_size']}")
self.logger.info(f" Validation batch size: {val_info['batch_size']}")
self.logger.info("Dataloaders built successfully")
def build_optimizer(self):
"""Build optimizer and learning rate scheduler."""
self.logger.info("Building optimizer...")
train_config = self.config['training']
opt_config = train_config['optimizer']
# Get model parameters
params = self.model.trainable_params()
# Create optimizer
if opt_config['type'] == 'AdamWeightDecay':
# Use standard Adam with weight decay for better Ascend compatibility
self.optimizer = nn.Adam(
params=params,
learning_rate=opt_config['learning_rate'],
beta1=opt_config['beta1'],
beta2=opt_config['beta2'],
eps=float(opt_config['eps']),
weight_decay=opt_config['weight_decay']
)
self.logger.info("Using Adam optimizer with weight decay for Ascend compatibility")
elif opt_config['type'] == 'Adam':
self.optimizer = nn.Adam(
params=params,
learning_rate=opt_config['learning_rate'],
beta1=opt_config.get('beta1', 0.9),
beta2=opt_config.get('beta2', 0.999),
eps=float(opt_config.get('eps', 1e-8)),
weight_decay=opt_config.get('weight_decay', 0.0)
)
elif opt_config['type'] == 'SGD':
self.optimizer = nn.SGD(
params=params,
learning_rate=opt_config['learning_rate'],
momentum=opt_config.get('momentum', 0.9),
weight_decay=opt_config.get('weight_decay', 0.0)
)
else:
raise ValueError(f"Unsupported optimizer: {opt_config['type']}")
# Learning rate scheduler
lr_config = train_config.get('lr_scheduler', {})
if lr_config.get('type') == 'CosineAnnealingLR':
# This would need custom implementation in MindSpore
self.logger.info("Note: CosineAnnealingLR scheduler not implemented")
self.logger.info(f" Optimizer built: {opt_config['type']}")
self.logger.info(f" Learning rate: {opt_config['learning_rate']}")
self.logger.info(f" Weight decay: {opt_config['weight_decay']}")
def build_loss_function(self):
"""Build loss function."""
self.logger.info(" Building loss function...")
loss_config = self.config['training']['loss']
if loss_config['type'] == 'GaussianLoss':
self.loss_fn = GaussianLoss(**loss_config['args'])
else:
raise ValueError(f"Unsupported loss function: {loss_config['type']}")
self.logger.info(f" Loss function built: {loss_config['type']}")
def create_callbacks(self):
"""Create training callbacks."""
callbacks = []
# Loss monitor
log_interval = self.config.get('logging', {}).get('log_interval', 50)
callbacks.append(LossMonitor(log_interval))
# Time monitor
callbacks.append(TimeMonitor())
# Checkpoint callback
checkpoint_config = self.config.get('logging', {}).get('checkpoint', {})
save_dir = Path(checkpoint_config.get('save_dir', './checkpoints'))
save_dir.mkdir(parents=True, exist_ok=True)
config_ckpt = CheckpointConfig(
save_checkpoint_steps=checkpoint_config.get('save_checkpoint_steps', 1000),
keep_checkpoint_max=checkpoint_config.get('keep_checkpoint_max', 10)
)
callbacks.append(
ModelCheckpoint(
prefix='gaussianlss',
directory=str(save_dir),
config=config_ckpt
)
)
return callbacks
def train(self):
"""Main training loop."""
self.logger.info(" Starting training...")
# Build all components
self.build_model()
self.build_dataloaders()
self.build_optimizer()
self.build_loss_function()
# Create training dataset
train_dataset = self.train_dataloader.create_dataset()
val_dataset = self.val_dataloader.create_dataset()
# Create model wrapper
net_with_loss = GaussianLSSWithLoss(self.model, self.loss_fn)
train_net = nn.TrainOneStepCell(net_with_loss, self.optimizer)
# Training configuration
train_config = self.config['training']
epochs = train_config['epochs']
# Create callbacks
callbacks = self.create_callbacks()
# Training loop
self.logger.info(f"Training for {epochs} epochs...")
train_losses = []
val_losses = []
for epoch in range(epochs):
epoch_start_time = time.time()
# Training phase
train_net.set_train(True)
train_loss = self.train_epoch(train_net, train_dataset, epoch)
train_losses.append(train_loss)
# Validation phase
if epoch % train_config.get('val_interval', 5) == 0:
val_loss = self.validate_epoch(val_dataset, epoch)
val_losses.append(val_loss)
epoch_time = time.time() - epoch_start_time
self.logger.info(
f"Epoch {epoch+1}/{epochs} - "
f"Train Loss: {train_loss:.4f} - "
f"Time: {epoch_time:.2f}s"
)
# Save checkpoint
if epoch % train_config.get('save_interval', 10) == 0:
self.save_checkpoint(epoch)
# Plot training curves
self.plot_training_results(train_losses, val_losses)
self.logger.info(" Training completed!")
def train_epoch(self, train_net, dataset, epoch):
"""Train for one epoch."""
train_net.set_train(True)
total_loss = 0.0
step_count = 0
dataset_size = dataset.get_dataset_size()
print("/r/ndataset_size:", dataset_size)
dataset_iter = dataset.create_dict_iterator(output_numpy=False, num_epochs=1)
for step, batch in enumerate(dataset_iter):
images = batch['images']
intrinsics = batch['intrinsics']
extrinsics = batch['extrinsics']
targets = batch['targets']
boxes_3d = batch['boxes_3d']
labels = batch['labels']
# Forward pass
loss = train_net(images, intrinsics, extrinsics, targets)
total_loss += loss.asnumpy()
step_count += 1
# Log progress
if step % self.config.get('logging', {}).get('log_interval', 50) == 0:
self.logger.info(
f"Epoch {epoch+1}, Step {step}: Loss = {loss.asnumpy():.4f}"
)
return total_loss / step_count if step_count > 0 else 0.0
def validate_epoch(self, dataset, epoch):
"""Validate for one epoch."""
self.model.set_train(False)
total_loss = 0.0
step_count = 0
dataset_iter = dataset.create_tuple_iterator(output_numpy=False)
for step, batch in enumerate(dataset_iter):
images, intrinsics, extrinsics, targets, boxes_3d, labels = batch
# Forward pass
predictions = self.model(images, intrinsics, extrinsics)
loss_dict = self.loss_fn(predictions, targets)
loss = loss_dict['total_loss']
total_loss += loss.asnumpy()
step_count += 1
avg_loss = total_loss / step_count if step_count > 0 else 0.0
self.logger.info(f"Validation Loss: {avg_loss:.4f}")
return avg_loss
def save_checkpoint(self, epoch):
"""Save model checkpoint."""
checkpoint_dir = Path(self.config.get('logging', {}).get('checkpoint', {}).get('save_dir', './checkpoints'))
checkpoint_dir.mkdir(parents=True, exist_ok=True)
checkpoint_path = checkpoint_dir / f'gaussianlss_epoch_{epoch+1}.ckpt'
ms.save_checkpoint(self.model, str(checkpoint_path))
self.logger.info(f" Checkpoint saved: {checkpoint_path}")
def plot_training_results(self, train_losses, val_losses):
"""Plot and save training results."""
vis_dir = Path(self.config.get('logging', {}).get('vis_save_dir', './visualizations'))
vis_dir.mkdir(parents=True, exist_ok=True)
plot_training_curves(
train_losses=train_losses,
val_losses=val_losses,
save_path=str(vis_dir / 'training_curves.png')
)
class GaussianLSSWithLoss(nn.Cell):
“”“Model wrapper with loss calculation.”“”
def __init__(self, model, loss_fn):
super().__init__()
self.model = model
self.loss_fn = loss_fn
def construct(self, images, intrinsics, extrinsics, targets):
predictions = self.model(images, intrinsics, extrinsics)
loss_dict = self.loss_fn(predictions, targets)
return loss_dict['total_loss']
def main():
“”“Main function.”“”
parser = argparse.ArgumentParser(description='Train GaussianLSS on NuScenes')
parser.add_argument(
'--config',
type=str,
default='configs/nuscenes_ascend.yaml',
help='Path to configuration file'
)
parser.add_argument(
'--resume',
type=str,
default=None,
help='Path to checkpoint to resume from'
)
args = parser.parse_args()
# Validate config file
config_path = Path(args.config)
if not config_path.exists():
print(f" Configuration file not found: {config_path}")
sys.exit(1)
print(" Starting GaussianLSS Training")
print(f" Configuration: {config_path}")
print(f" Resume from: {args.resume or 'None'}")
try:
# Create trainer
trainer = GaussianLSSTrainer(str(config_path))
# Start training
trainer.train()
print(" Training completed successfully!")
except Exception as e:
print(f" Training failed: {e}")
import traceback
traceback.print_exc()
sys.exit(1)
if name == ‘main’:
main()
启智社区和昇腾大模型平台都有mindspore 2.5或者2.6的环境, 你可以试试,免费的,就是每天用使用量的限制:
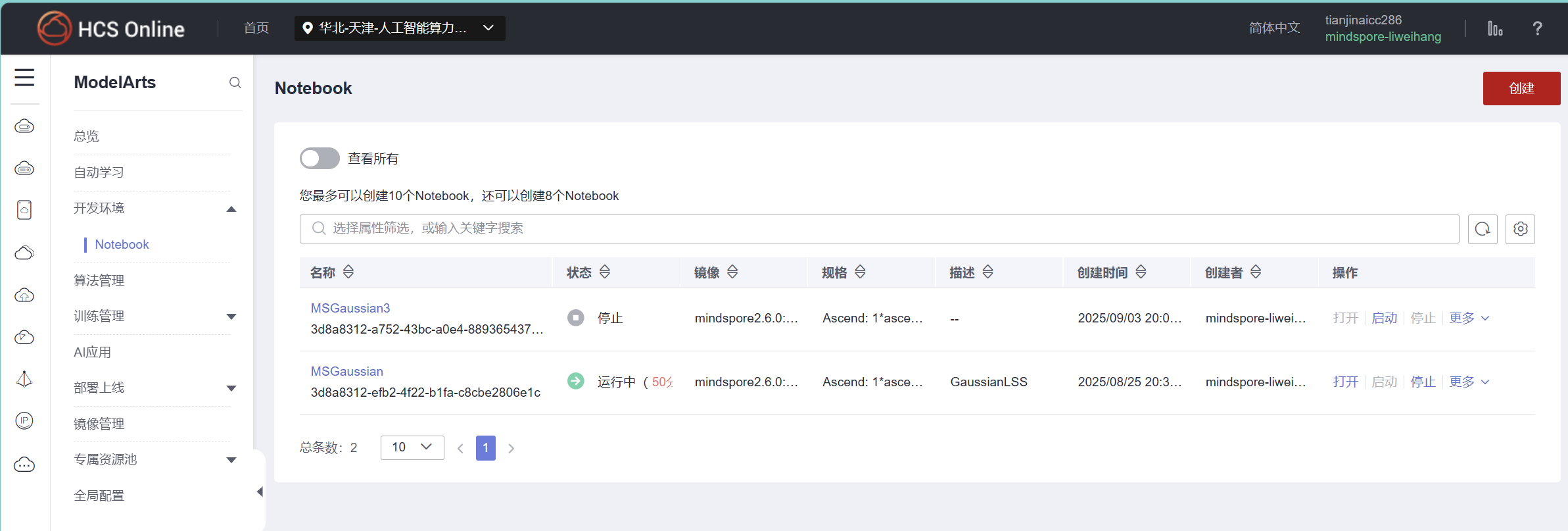
你这边用的是华为云的modelarts吗?哪个区的?910a还是910b的,我印象中华为云modelarts上应该没有2.6的镜像环境?
我用的是这一个下面的这一个,910b的。
是的,我去查了启智社区,确实看到有免费的,不过只有2.5版本的,而且使用方式和modelart区别比较大,我正在探索中,这可能比较费时间。因此,如果能够找到解决的方法,我还是更希望能在modelart上调试。
此话题已在最后回复的 60 分钟后被自动关闭。不再允许新回复。