Audio Spectrogram Transformer 模型解读
论文概述
原论文名为《Audio Spectrogram Transformer》,主要探讨了如何将Transformer架构应用于音频分类任务。作者提出了一种基于音频频谱图的Transformer模型(AST),并通过在多个音频数据集上的实验验证了其有效性。实验结果显示,AST在多个音频分类任务上取得了state-of-the-art的性能,尤其是在AudioSet、ESC-50和Speech Commands数据集上表现优异。
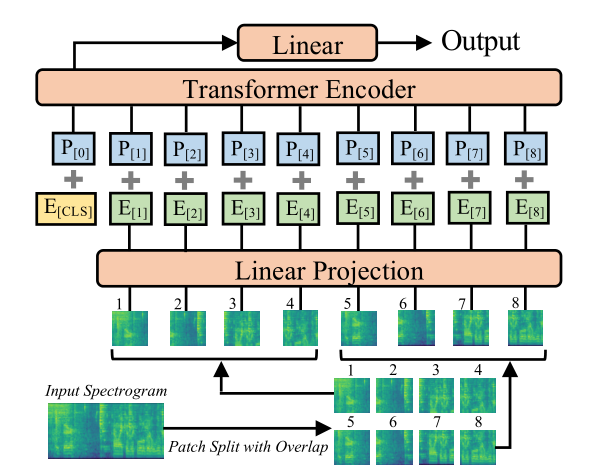
ast主要模型架构
研究背景
近年来,Transformer架构在自然语言处理和计算机视觉领域取得了巨大成功。然而,在音频处理领域,Transformer的应用相对较少。传统的音频分类方法通常依赖于卷积神经网络(CNN)或循环神经网络(RNN),这些方法在处理长序列音频数据时存在一定的局限性。Transformer的自注意力机制能够更好地捕捉音频信号中的全局依赖关系,因此作者提出了将Transformer应用于音频分类任务的想法。
论文研究方法
- 基于Transformer的音频分类模型: 作者提出了一种基于音频频谱图的Transformer模型(AST),该模型将音频信号转换为频谱图,并将其作为输入传递给Transformer编码器。通过这种方式,模型能够捕捉音频信号中的全局依赖关系。 2. ImageNet预训练: 作者发现,通过在ImageNet数据集上预训练Transformer编码器,可以显著提高模型在音频分类任务上的性能。这种跨模态的预训练策略为音频分类任务提供了新的思路。 3. 多数据集实验: 作者在多个音频数据集上进行了实验,包括AudioSet、ESC-50和Speech Commands。实验结果表明,AST在这些数据集上均取得了state-of-the-art的性能。
论文模型及训练细节
频谱图输入
输入表示:AST的输入是音频信号的频谱图,通常是通过短时傅里叶变换(STFT)或梅尔频谱图(Mel-spectrogram)生成的。频谱图可以被视为一个二维图像,其中时间轴和频率轴分别对应图像的宽度和高度。
预处理:在输入Transformer之前,频谱图会被分割成固定大小的patch(类似于图像中的小块),这些patch会被展平并作为Transformer的输入。
模型架构细节
Patch Embedding:每个patch会被线性投影到一个固定维度的嵌入向量,这些嵌入向量会被输入到Transformer中。
Positional Encoding:由于Transformer本身不包含位置信息,AST会为每个patch添加位置编码,以保留其在频谱图中的位置信息。
Self-Attention Mechanism:Transformer的核心是自注意力机制,它允许模型在处理每个patch时考虑到所有其他patch的信息。这种机制使得AST能够捕捉音频中的全局依赖关系。
Multi-Head Attention:AST使用了多头注意力机制,允许模型在不同的表示子空间中学习不同的特征。
Feed-Forward Network:在自注意力层之后,AST会通过一个前馈神经网络进一步处理特征。
预训练与微调
ImageNet预训练:AST的Transformer部分是在ImageNet数据集上进行预训练的,这使得模型能够从大规模图像数据中学习到有用的特征表示。
微调:在音频分类任务中,AST会在特定的音频数据集(如AudioSet、ESC-50等)上进行微调,以适应具体的任务需求。
创新点分析
- 将Transformer架构应用于音频分类任务: 传统的音频分类方法通常依赖于CNN或RNN,而AST首次将Transformer架构应用于音频分类任务,并取得了显著的效果。这一创新为音频处理领域提供了新的研究方向。 2. 跨模态预训练策略: 作者通过在ImageNet数据集上预训练Transformer编码器,显著提高了模型在音频分类任务上的性能。这种跨模态的预训练策略为音频分类任务提供了新的思路。 3. 全局依赖关系的捕捉: Transformer的自注意力机制能够更好地捕捉音频信号中的全局依赖关系,这使得AST在处理长序列音频数据时具有优势。
结果
作者在多个音频数据集上进行了实验,以下是AST在这些数据集上的训练细节和结果: AudioSet:mAP(mean Average Precision)为0.485,相比之前的state-of-the-art模型(PSLA)提高了2.3%。

消融实验:作者进行了多项消融实验,验证了不同组件对模型性能的影响。例如,去除了ImageNet预训练后,模型性能显著下降,表明预训练对模型的重要性


ESC-50:准确率为95.6%,相比之前的state-of-the-art模型(PSLA)提高了1.2%。
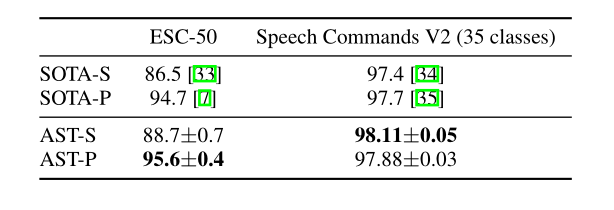
Speech Commands:准确率为98.1%,相比之前的state-of-the-art模型(PSLA)提高了0.5%。
使用MindNLP进行模型评估
我们将使用MindNLP加载AST模型,并在ESC-50数据集上进行评估。以下是评估与推理的结果:
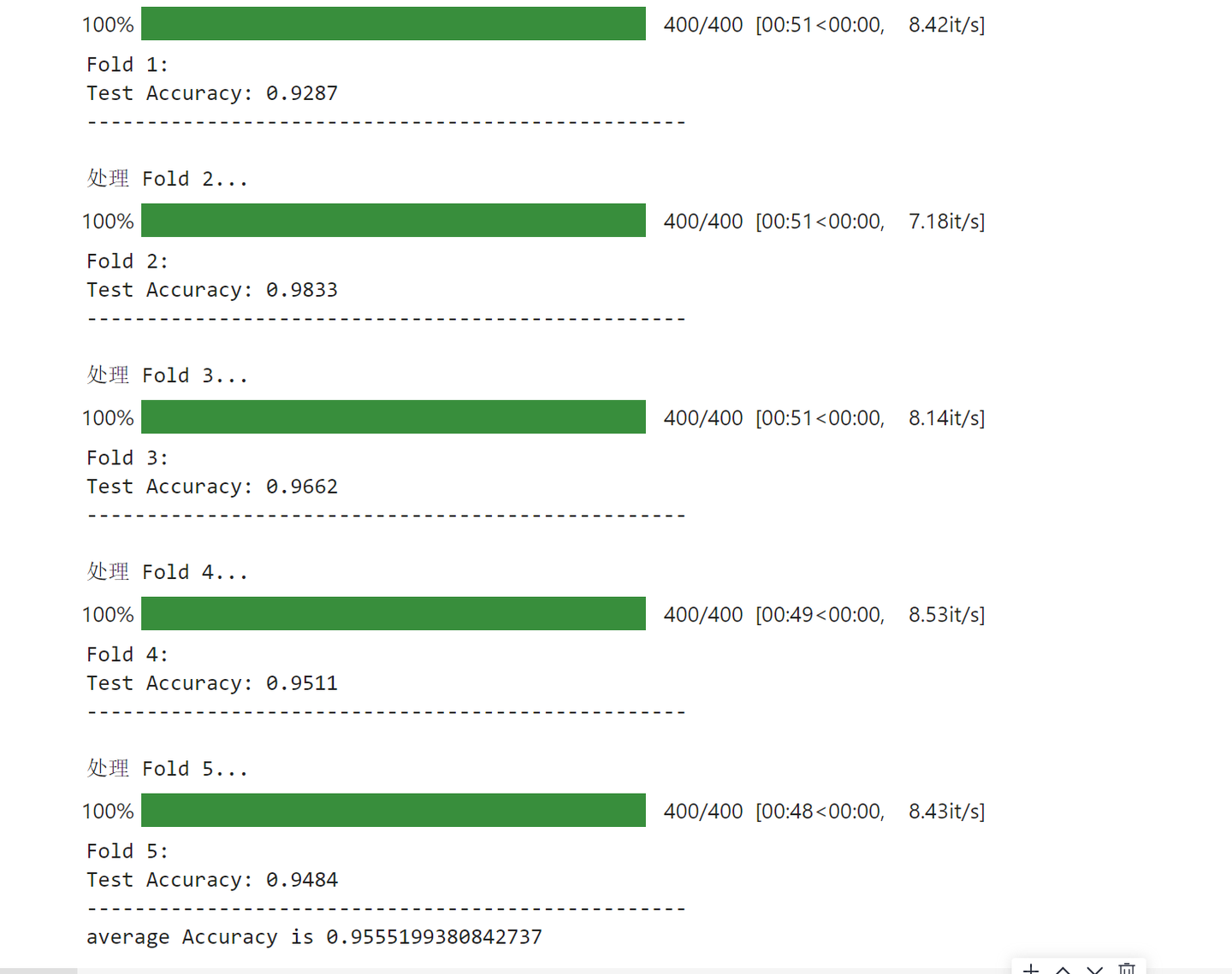

mindnlp相关实现评估推理代码请看以下连接:GitHub - guyueyuan/audio_spectrogram_transformer_mindnlp: audio_spectrogram_transformer模型解读 · GitHub
结论
- 音频谱图Transformer模型的有效性 该论文提出的音频谱图Transformer(AST)模型在音频分类任务中表现出色,特别是在AudioSet、ESC-50和Speech Commands数据集上取得了显著的性能提升。 2. ImageNet预训练的重要性 通过使用ImageNet预训练的视觉Transformer模型作为基础,AST模型能够更好地捕捉音频谱图中的全局特征,从而提高了分类精度。 3. 模型架构的优化 AST模型通过引入Transformer架构,能够有效地处理长序列数据,并且在音频分类任务中表现出比传统卷积神经网络(CNN)更好的性能。 4. 消融实验的验证 通过一系列消融实验,论文验证了不同组件(如位置编码、多头注意力机制等)对模型性能的贡献,进一步证明了AST模型设计的合理性。 5. 跨数据集的泛化能力 AST模型不仅在AudioSet上表现优异,还在ESC-50和Speech Commands数据集上展现了强大的泛化能力,表明该模型适用于多种音频分类任务。
推荐
推荐各位开发者使用 Mindnlp 来加载并复现该模型。 简洁接口:Mindnlp 提供了与 PyTorch 类似的简洁接口,降低了学习和使用的难度。 快速复现:开发者可以迅速加载和复现模型,节省时间和精力。 详尽文档:详尽的文档和示例代码帮助开发者更好地理解和应用各种功能。 多任务支持:Mindnlp 支持多种自然语言处理任务,如文本分类、命名实体识别等,适应不同的需求。 强大社区:拥有一个支持性强的社区,提供技术交流和经验分享的机会。